




ж–°й—»иҜҰжғ…
ж–°й—»жҗңзҙў
жөӘжҪ® жңҚеҠЎеҷЁ OGAIиҜҰи§ЈпјҡAIStationи°ғеәҰе№іеҸ°и§ЈеҶіеӨ§жЁЎеһӢи®ӯз»ғзҡ„й•ҝж—¶гҖҒй«ҳж•ҲгҖҒжҢҒз»ӯд№Ӣйҡҫйўҳ еӣӣе·қ жҲҗйғҪ 科жұҮ科жҠҖ ITжңҚеҠЎе•Ҷ
еӨ§жЁЎеһӢжҳҜеҪ“еүҚйҖҡз”Ёдәәе·ҘжҷәиғҪдә§дёҡеҸ‘еұ•еҲӣж–°зҡ„ж ёеҝғжҠҖжңҜпјҢзӣ®еүҚеӣҪеҶ…е·ІеҸ‘еёғзҡ„з”ҹжҲҗејҸAIжЁЎеһӢи¶…иҝҮдәҶ100дёӘгҖӮйқўеҗ‘д»ҘеӨ§жЁЎеһӢдёәж ёеҝғзҡ„з”ҹжҲҗејҸAIејҖеҸ‘дёҺеә”з”ЁеңәжҷҜпјҢиҝ‘ж—ҘжөӘжҪ®дҝЎжҒҜеҸ‘еёғдәҶеӨ§жЁЎеһӢжҷәз®—иҪҜ件ж ҲOGAIпјҲOpen GenAI InfraпјүвҖ”вҖ”вҖңе…ғи„‘з”ҹжҷәвҖқпјҢдёәеӨ§жЁЎеһӢдёҡеҠЎжҸҗдҫӣдәҶе…Ёж Ҳе…ЁжөҒзЁӢзҡ„жҷәз®—иҪҜ件ж ҲпјҢеҢ…жӢ¬AIз®—еҠӣзі»з»ҹзҺҜеўғйғЁзҪІгҖҒз®—еҠӣи°ғеәҰдҝқйҡңгҖҒжЁЎеһӢејҖеҸ‘з®ЎзҗҶзӯүгҖӮOGAIиҪҜ件ж Ҳз”ұ5еұӮжһ¶жһ„з»„жҲҗпјҢд»ҺL0еҲ°L4еҲҶеҲ«еҜ№еә”дәҺеҹәзЎҖи®ҫж–ҪеұӮзҡ„жҷәз®—дёӯеҝғOSдә§е“ҒгҖҒзі»з»ҹзҺҜеўғеұӮзҡ„PODsysдә§е“ҒгҖҒи°ғеәҰе№іеҸ°еұӮзҡ„AIStationдә§е“ҒгҖҒжЁЎеһӢе·Ҙе…·еұӮзҡ„YLinkдә§е“Ғе’ҢеӨҡжЁЎзәіз®ЎеұӮзҡ„MModelдә§е“ҒгҖӮ
е…¶дёӯL2еұӮAIStationжҳҜйқўеҗ‘еӨ§жЁЎеһӢејҖеҸ‘зҡ„AIз®—еҠӣи°ғеәҰе№іеҸ°пјҢAIStationй’ҲеҜ№еӨ§жЁЎеһӢи®ӯз»ғдёӯзҡ„иө„жәҗдҪҝз”ЁдёҺи°ғеәҰгҖҒи®ӯз»ғжөҒзЁӢдёҺдҝқйҡңгҖҒз®—жі•дёҺеә”з”Ёз®ЎзҗҶзӯүж–№йқўиҝӣиЎҢдәҶзі»з»ҹжҖ§дјҳеҢ–пјҢе…·еӨҮеӨ§жЁЎеһӢж–ӯзӮ№з»ӯи®ӯиғҪеҠӣпјҢдҝқиҜҒй•ҝж—¶й—ҙжҢҒз»ӯи®ӯз»ғгҖӮAIStationж”Ҝж’‘жөӘжҪ®дҝЎжҒҜвҖңжәҗвҖқеӨ§жЁЎеһӢзҡ„и®ӯз»ғз®—еҠӣж•ҲзҺҮиҫҫеҲ°44.8%гҖӮжҹҗеӨ§еһӢе•Ҷдёҡ银иЎҢеҹәдәҺAIStationжү“йҖ зҡ„еӨ§и§„模并иЎҢиҝҗз®—йӣҶзҫӨпјҢеё®еҠ©е…¶е……еҲҶеҸ‘жҺҳи®Ўз®—жҪңиғҪиҝӣиЎҢеӨ§жЁЎеһӢи®ӯз»ғпјҢ并иҚЈиҺ·2022 IDCвҖңжңӘжқҘж•°еӯ—еҹәзЎҖжһ¶жһ„йўҶеҶӣиҖ…вҖқеҘ–йЎ№гҖӮ
жң¬ж–Үе°ҶйҮҚзӮ№и®Ёи®әеӨ§жЁЎеһӢи®ӯз»ғйқўдёҙзҡ„жҢ‘жҲҳгҖҒAIStationеҰӮдҪ•жҸҗеҚҮеӨ§жЁЎеһӢи®ӯз»ғж•ҲзҺҮпјҢд»ҘеҸҠеҸ–еҫ—зҡ„ж•ҲжһңгҖӮ

еӨ§жЁЎеһӢи®ӯз»ғйқўдёҙе·ЁеӨ§жҢ‘жҲҳ
в–җ еӨ§жЁЎеһӢи®ӯз»ғе·ЁеӨ§з®—еҠӣжҲҗжң¬е’Ңз®—еҠӣеҲ©з”Ёйҡҫйўҳ
в–җ иҖ—ж—¶дё”з»ҙжҠӨеӨҚжқӮзҡ„еӨҡз§ҚзҪ‘з»ңе…је®№йҖӮй…Қ
еӨ§жЁЎеһӢи®ӯз»ғиҝҮзЁӢдёӯпјҢжҲҗеҚғдёҠдёҮйў—GPUдјҡеңЁиҠӮзӮ№еҶ…е’ҢиҠӮзӮ№й—ҙдёҚж–ӯең°иҝӣиЎҢйҖҡдҝЎгҖӮдёәдәҶиҺ·еҫ—жңҖдјҳзҡ„и®ӯз»ғж•ҲжһңпјҢеҚ•еҸ°GPUжңҚеҠЎеҷЁдјҡжҗӯиҪҪеӨҡеј InfiniBandгҖҒROCEзӯүй«ҳжҖ§иғҪзҪ‘еҚЎпјҢдёәиҠӮзӮ№й—ҙйҖҡдҝЎжҸҗдҫӣй«ҳеҗһеҗҗгҖҒдҪҺ时延зҡ„жңҚеҠЎгҖӮдҪҶдёҚеҗҢзҡ„зҪ‘з»ңж–№жЎҲеҗ„жңүдјҳеҠЈпјҢInfiniBandеӣ жҖ§иғҪдјҳејӮе·Іиў«е…¬и®ӨдёәеӨ§жЁЎеһӢи®ӯз»ғзҡ„йҰ–йҖүпјҢдҪҶе…¶жҲҗжң¬иҫғй«ҳпјӣRoCEиҷҪ然жҲҗжң¬иҫғдҪҺпјҢдҪҶеңЁеӨ§и§„жЁЎзҡ„зҪ‘з»ңзҺҜеўғдёӢпјҢе…¶жҖ§иғҪе’ҢзЁіе®ҡжҖ§дёҚеҰӮInfiniBandж–№жЎҲгҖӮеӣ жӯӨиҰҒжғіж»Ўи¶іеӨ§жЁЎеһӢи®ӯз»ғеҜ№йҖҡдҝЎзҡ„иҰҒжұӮпјҢе°ұиҰҒеҜ№йӣҶзҫӨзҪ‘з»ңдёӯзҡ„йҖҡдҝЎи®ҫеӨҮйҖӮй…ҚдҪҝз”Ёе’ҢзҪ‘з»ңжғ…еҶөиҝӣиЎҢжҺўзҙўе’Ңи®ҫи®ЎгҖӮ
в–җ дёҚзЁіе®ҡзҡ„еӨ§жЁЎеһӢи®ӯз»ғе’Ңй«ҳй—Ёж§ӣзҡ„зі»з»ҹзә§еҲ«дјҳеҢ–
еӨ§жЁЎеһӢи®ӯз»ғиҝҮзЁӢжҜ”дј з»ҹзҡ„еҲҶеёғејҸи®ӯз»ғеӨҚжқӮпјҢи®ӯз»ғе‘Ёжңҹй•ҝиҫҫж•°жңҲгҖӮйӣҶзҫӨи®Ўз®—ж•ҲеҠӣдҪҺгҖҒж•…йҡңйў‘еҸ‘дё”еӨ„зҗҶеӨҚжқӮпјҢдјҡеҜјиҮҙи®ӯз»ғдёӯж–ӯеҗҺдёҚиғҪеҸҠж—¶жҒўеӨҚпјҢд»ҺиҖҢдјҡйҷҚдҪҺеӨ§жЁЎеһӢи®ӯз»ғзҡ„жҲҗеҠҹжҰӮзҺҮпјҢд№ҹдјҡдҪҝеҫ—еӨ§жЁЎеһӢи®ӯз»ғжҲҗжң¬еұ…й«ҳдёҚдёӢгҖӮеӣ жӯӨпјҢеӨ§жЁЎеһӢеҜ№и®ӯз»ғзҡ„зЁіе®ҡжҖ§гҖҒж•…йҡңжЈҖжөӢдёҺи®ӯз»ғе®№й”ҷжҸҗеҮәдәҶжӣҙй«ҳзҡ„иҰҒжұӮгҖӮеҗҢж—¶з®ҖеҢ–еӨ§жЁЎеһӢеҲҶеёғејҸд»»еҠЎжҸҗдәӨгҖҒе®һзҺ°жҷәиғҪдёҺиҮӘеҠЁеҢ–зҡ„д»»еҠЎиө„жәҗеҢ№й…Қе’Ңи®ӯз»ғеҒҘеЈ®жҖ§д№ҹжҳҜжҸҗеҚҮи®ӯз»ғж•ҲзҺҮзҡ„йҮҚиҰҒдҝқиҜҒгҖӮ
MetaеңЁи®ӯз»ғжЁЎеһӢдҪ“йҮҸдёҺGPT3规模зӣёеҪ“зҡ„Open Pre-trained Transformer (OPT)-175Bж—¶пјҢйҒҮеҲ°зҡ„дёҖеӨ§е·ҘзЁӢй—®йўҳе°ұжҳҜи®ӯз»ғдёҚзЁіе®ҡгҖӮеҰӮдёӢеӣҫжүҖзӨәпјҢеҸҜд»ҘзңӢеҲ°жңүи®ёеӨҡи®ӯз»ғеҒңжӯўзҡ„ж—¶й—ҙиҠӮзӮ№пјҢеҺҹеӣ жңүGPUжҺүеҚЎгҖҒGPUжҖ§иғҪејӮеёёеҜјиҮҙи®ӯз»ғж„ҸеӨ–дёӯж–ӯзӯүгҖӮи®ӯз»ғзЁіе®ҡжҖ§е’Ңжңүж•Ҳзҡ„ж–ӯзӮ№з»ӯи®ӯжҳҜзӣ®еүҚеӨ§жЁЎеһӢи®ӯз»ғдёӯдәҹеҫ…и§ЈеҶізҡ„й—®йўҳгҖӮ
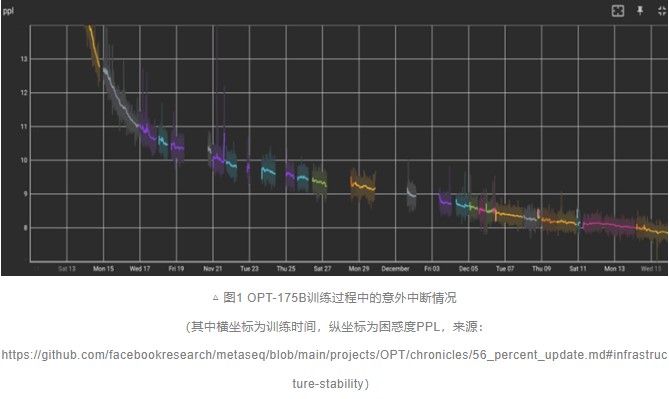
жҖ»д№ӢпјҢеңЁи¶…еӨ§и§„жЁЎеҲҶеёғејҸзҺҜеўғдёӢејҖеұ•еӨ§жЁЎеһӢи®ӯз»ғпјҢеҰӮжһңжғіиҰҒзј©зҹӯи®ӯз»ғе‘ЁжңҹгҖҒйҷҚдҪҺи®ӯз»ғжҲҗжң¬пјҢе°ұйңҖиҰҒи§ЈеҶіз®—еҠӣи°ғеәҰгҖҒзҪ‘з»ңйҖҡдҝЎгҖҒи®ӯз»ғзЁіе®ҡжҖ§зӯүеҗ„з§ҚжҢ‘жҲҳгҖӮдёҚд»…иҰҒзҒөжҙ»гҖҒе……еҲҶең°еҲ©з”ЁйӣҶзҫӨеҶ…зҡ„жүҖжңүиө„жәҗпјҢйҖҡиҝҮеӨҡз§ҚжүӢж®өдјҳеҢ–ж•°жҚ®дҪҝз”ЁгҖҒйҖҡи®ҜпјҢиҝҳиҰҒеҸҠж—¶еӨ„зҗҶеӨ§и§„жЁЎи®Ўз®—йӣҶзҫӨзҡ„ејӮеёёгҖӮ
AIStationе…ЁжөҒзЁӢз®ҖеҢ–е’ҢжҸҗйҖҹеӨ§жЁЎеһӢи®ӯз»ғ
жөӘжҪ®дҝЎжҒҜAIStationжҸҗдҫӣдәҶзі»з»ҹжҖ§иҪҜзЎ¬дёҖдҪ“дјҳеҢ–зҡ„е№іеҸ°дёҺиҪҜ件ж ҲиғҪеҠӣпјҢжқҘдҝқйҡңеӨ§жЁЎеһӢзҡ„и®ӯз»ғйңҖжұӮгҖӮAIStationе№іеҸ°д»Һиө„жәҗдҪҝз”ЁдёҺи°ғеәҰгҖҒи®ӯз»ғжөҒзЁӢдёҺдҝқйҡңгҖҒз®—жі•дёҺеә”з”Ёзӯүи§’еәҰиҝӣиЎҢдәҶзі»з»ҹжҖ§зҡ„дјҳеҢ–пјҢе®һзҺ°дәҶеҜ№еӨ§жЁЎеһӢи®ӯз»ғзҡ„з«ҜеҲ°з«ҜдјҳеҢ–е’ҢеҠ йҖҹгҖӮ
в–җ жҜ«з§’зә§и°ғеәҰпјҢй«ҳж•ҲдҪҝз”ЁеӨ§и§„жЁЎз®—еҠӣпјҢи§ЈеҶіз®—еҠӣеҲ©з”ЁдҪҺйҡҫйўҳ
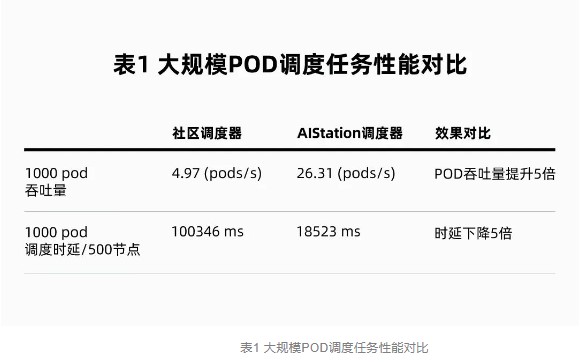
AIStationеңЁеӨ§жЁЎеһӢи®ӯз»ғе®һи·өдёӯпјҢй’ҲеҜ№дә‘еҺҹз”ҹи°ғеәҰзі»з»ҹжҖ§иғҪеҒҡдәҶдјҳеҢ–пјҢе®һзҺ°дәҶдёҠеҚғPODжһҒйҖҹеҗҜеҠЁе’ҢзҺҜеўғе°ұз»ӘгҖӮеҰӮдёӢиЎЁжүҖзӨәпјҢAIStationи°ғеәҰеҷЁдёҺеҺҹз”ҹзӨҫеҢәзүҲзӣёжҜ”пјҢиғҪеӨ§е№…жҸҗеҚҮеӨ§и§„жЁЎPODд»»еҠЎзҡ„и°ғеәҰжҖ§иғҪпјҢе°Өе…¶иғҪдҝқиҜҒеӨ§жЁЎеһӢи®ӯз»ғзҡ„и®Ўз®—иө„жәҗзҡ„и°ғеәҰдҪҝз”ЁгҖӮ
жӯӨеӨ–пјҢAIStationе№іеҸ°иғҪеӨҹж”ҜжҢҒеӨ§жЁЎеһӢзү№жңүзҡ„ејҖеҸ‘жЁЎејҸпјҢжҸҗдҫӣеӨҡз§Қе°әеәҰдҪңдёҡиө„жәҗдҪҝз”Ёж–№ејҸпјҢеҢ…жӢ¬е°Ҹе°әеәҰиө„жәҗи°ғеәҰпјҢеӨ§е°әеәҰиө„жәҗи°ғеәҰгҖҒй«ҳжҖ§иғҪи°ғеәҰзӯүгҖӮз®—еҠӣи°ғеәҰеҷЁйҖҡиҝҮеҠЁжҖҒгҖҒжҷәиғҪең°з®ЎзҗҶе’Ңи°ғй…ҚйӣҶзҫӨи®Ўз®—иө„жәҗпјҢеҲ¶е®ҡеҗҲзҗҶзҡ„дҪңдёҡжү§иЎҢи®ЎеҲ’пјҢд»ҘжңҖеӨ§йҷҗеәҰең°еҲ©з”Ёиө„жәҗпјҢж»Ўи¶іеҗ„зұ»и®ӯз»ғд»»еҠЎзҡ„时延е’ҢеҗһеҗҗйңҖжұӮпјҢдҝқиҜҒдҪңдёҡй«ҳж•ҲзЁіе®ҡиҝҗиЎҢпјҢе®һзҺ°з®—еҠӣе№іеҸ°й«ҳеҲ©з”ЁзҺҮгҖҒејәжү©еұ•жҖ§гҖҒй«ҳе®№й”ҷжҖ§гҖӮ
йҖҡиҝҮеӨҡз§Қиө„жәҗй«ҳж•Ҳз®ЎзҗҶе’Ңи°ғеәҰзӯ–з•ҘпјҢAIStationиғҪе®һзҺ°жҜ«з§’зә§и°ғеәҰпјҢе°Ҷж•ҙдҪ“иө„жәҗеҲ©з”ЁзҺҮжҸҗеҚҮеҲ°70%д»ҘдёҠпјҢеё®еҠ©е®ўжҲ·жӣҙеҘҪең°еҲ©з”Ёи®Ўз®—йӣҶзҫӨз®—еҠӣпјҢе……еҲҶеҸ‘жҢҘз®—еҠӣд»·еҖјгҖӮ
в–җ й«ҳж•ҲзҪ‘з»ңиө„жәҗз®ЎзҗҶпјҢеӨҡеҚЎеҠ йҖҹжҜ”иҫҫ90%пјҢжһҒиҮҙеҠ йҖҹи®ӯз»ғиҝҮзЁӢ
AIStationе®ҡд№үдәҶдә’зӣёзӢ¬з«Ӣзҡ„и®Ўз®—й«ҳжҖ§иғҪзҪ‘з»ңгҖҒеӯҳеӮЁй«ҳжҖ§иғҪзҪ‘з»ңпјҢ并且ж”ҜжҢҒдәӨжҚўжңәзә§еҲ«зҡ„иө„жәҗи°ғеәҰпјҢеҮҸе°‘и·ЁдәӨжҚўжңәжөҒйҮҸпјҢеҗҢж—¶е…·еӨҮзҪ‘з»ңж•…йҡңиҮӘеҠЁиҜҶеҲ«е’ҢеӨ„зҗҶеҠҹиғҪгҖӮй’ҲеҜ№еӨ§жЁЎеһӢи®ӯз»ғйҖҡдҝЎиҰҒжұӮй«ҳзҡ„еңәжҷҜпјҢAIStationжҸҗдҫӣйӣҶзҫӨжӢ“жү‘ж„ҹзҹҘиғҪеҠӣпјҢе®№еҷЁзҪ‘з»ңдёҺйӣҶзҫӨзү©зҗҶзҪ‘з»ңдёҖиҮҙпјҢдҝқиҜҒдәҶе®№еҷЁдә’иҒ”жҖ§иғҪпјҢж»Ўи¶іи®ӯз»ғйҖҡдҝЎиҰҒжұӮгҖӮеҲҶеёғејҸйҖҡдҝЎдјҳеҢ–з»“еҗҲйӣҶзҫӨзҡ„InfiniBandжҲ– RoCEй«ҳжҖ§иғҪзҪ‘з»ңе’Ңдё“й—ЁдјҳеҢ–зҡ„йҖҡдҝЎжӢ“жү‘пјҢдҪҝеҫ—AIStationеңЁеҚғеҚЎи§„жЁЎйӣҶзҫӨжөӢиҜ•дёӯпјҢеӨҡеҚЎеҠ йҖҹжҜ”иҫҫеҲ°дәҶ90%гҖӮе°Өе…¶AIStationеҜ№еӨ§и§„жЁЎRoCEж— жҚҹзҪ‘з»ңдёӢзҡ„еӨ§жЁЎеһӢи®ӯз»ғд№ҹеҒҡдәҶзӣёеә”дјҳеҢ–пјҢе®һжөӢзҪ‘з»ңжҖ§иғҪзЁіе®ҡжҖ§иҫҫеҲ°дәҶдёҡз•Ңиҫғй«ҳж°ҙе№ігҖӮ
еҖҹеҠ©AIStationе№іеҸ°пјҢжҹҗеӨ§еһӢе•Ҷдёҡ银иЎҢе®һзҺ°дәҶдё»жөҒеӨ§жЁЎеһӢи®ӯз»ғжЎҶжһ¶пјҢеҰӮDeepSpeedгҖҒMegatron-LMе’ҢеӨ§иҜӯиЁҖжЁЎеһӢеңЁRoCEзҪ‘з»ңзҺҜеўғзҡ„и®ӯз»ғпјҢеҝ«йҖҹе®һзҺ°еӨ§жЁЎеһӢзҡ„иҗҪең°е®һи·өгҖӮ
в–җ еӨ§и§„жЁЎи®ӯз»ғзі»з»ҹзә§еҲ«дјҳеҢ–пјҢж•…йҡңеӨ„зҗҶж—¶й—ҙзј©зҹӯ90%пјҢжңҖеӨ§йҷҗеәҰйҷҚдҪҺе®һйӘҢжҲҗжң¬
еӨ§жЁЎеһӢд»»еҠЎжҸҗдәӨж—¶пјҢз»ҸеёёдјҡдјҙйҡҸзқҖеӨ§йҮҸзҡ„зҺҜеўғй…ҚзҪ®гҖҒдҫқиө–еә“йҖӮй…Қе’Ңи¶…еҸӮж•°и°ғж•ҙгҖӮAIStationиғҪеӨҹиҮӘеҠЁеҢ–й…ҚзҪ®и®Ўз®—гҖҒеӯҳеӮЁгҖҒзҪ‘з»ңзҺҜеўғпјҢеҗҢж—¶еҜ№дёҖдәӣеҹәжң¬зҡ„и¶…еҸӮж•°жҸҗдҫӣиҮӘе®ҡд№үдҝ®ж”№пјҢж–№дҫҝз”ЁжҲ·дҪҝз”ЁпјҢйҖҡиҝҮеҮ жӯҘе°ұиғҪеҗҜеҠЁеӨ§жЁЎеһӢеҲҶеёғејҸи®ӯз»ғпјҢзӣ®еүҚж”ҜжҢҒиҜёеӨҡеӨ§жЁЎеһӢи®ӯз»ғжЎҶжһ¶е’ҢејҖжәҗж–№жЎҲпјҢеҰӮMegatron-LMгҖҒDeepSpeedзӯүгҖӮ
AIStationеңЁеӨ§и§„жЁЎи®ӯз»ғйӣҶзҫӨдёҠеҲ©з”ЁиҮӘз ”ж•°жҚ®зј“еӯҳзі»з»ҹпјҢжҸҗй«ҳдәҶи®ӯз»ғеүҚгҖҒи®ӯз»ғдёӯзҡ„ж•°жҚ®иҜ»еҸ–йҖҹзҺҮпјҢеӨ§еӨ§еҮҸе°‘еҜ№еӯҳеӮЁзі»з»ҹе’ҢзҪ‘з»ңзҡ„дҫқиө–гҖӮй…ҚеҗҲдјҳеҢ–зҡ„и°ғеәҰзӯ–з•ҘпјҢдёҺзӣҙжҺҘдҪҝз”ЁеӯҳеӮЁзі»з»ҹзӣёжҜ”пјҢеҸҜи®©жЁЎеһӢи®ӯз»ғж•ҲзҺҮиҺ·еҫ—200%-300%зҡ„жҸҗеҚҮпјҢ硬件жҖ§иғҪ100%йҮҠж”ҫгҖӮ
еҒҘеЈ®жҖ§дёҺзЁіе®ҡжҖ§жҳҜй«ҳж•Ҳе®ҢжҲҗеӨ§жЁЎеһӢи®ӯз»ғзҡ„еҝ…иҰҒжқЎд»¶гҖӮAIStationй’ҲеҜ№иө„жәҗж•…йҡңзӯүйӣҶзҫӨзӘҒеҸ‘жғ…еҶөпјҢдјҡиҮӘеҠЁиҝӣиЎҢе®№й”ҷеӨ„зҗҶжҲ–иҖ…жү§иЎҢеј№жҖ§жү©зј©е®№зӯ–з•ҘпјҢдҝқиҜҒи®ӯз»ғд»»еҠЎдёӯж–ӯеҗҺиғҪд»ҘжңҖеҝ«йҖҹеәҰжҒўеӨҚпјҢдёәйңҖиҰҒй•ҝж—¶й—ҙи®ӯз»ғзҡ„еӨ§жЁЎеһӢжҸҗдҫӣеҸҜйқ зҺҜеўғпјҢе№іеқҮе°ҶејӮеёёж•…йҡңеӨ„зҗҶж—¶й—ҙзј©зҹӯ90%д»ҘдёҠгҖӮ
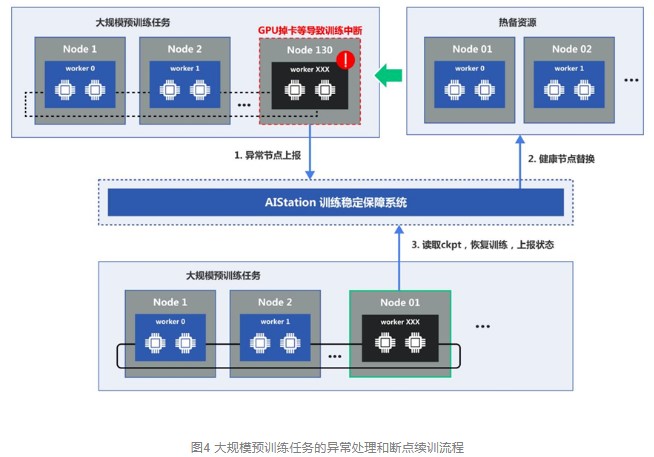
з»јдёҠпјҢй’ҲеҜ№еӨ§и§„жЁЎеҲҶеёғејҸи®Ўз®—пјҢAIStationеҶ…зҪ®еҲҶеёғејҸи®ӯз»ғиҮӘйҖӮеә”зі»з»ҹпјҢиҰҶзӣ–и®ӯз»ғзҡ„е…Ёз”ҹе‘Ҫе‘ЁжңҹпјҢж»Ўи¶ідәҶеӨ§жЁЎеһӢи®ӯз»ғзҡ„иҜёеӨҡиҜүжұӮпјҢжҸҗдҫӣиө„жәҗдҪҝз”Ёи§ҶеӣҫгҖҒи®Ўз®—дёҺзҪ‘з»ңи°ғеәҰзӯ–з•ҘгҖҒеҲҶеёғејҸи®ӯз»ғеҠ йҖҹгҖҒи®ӯз»ғзӣ‘жҺ§гҖҒи®ӯз»ғе®№й”ҷдёҺиҮӘж„ҲиғҪеҠӣпјҢеңЁеҠ йҖҹи®ӯз»ғзҡ„еҗҢж—¶пјҢиғҪеӨҹиҮӘеҠЁе®ҡдҪҚж•…йҡңе’ҢжҒўеӨҚд»»еҠЎпјҢдҝқиҜҒдәҶи®ӯз»ғзҡ„зЁіе®ҡжҖ§е’Ңж•ҲзҺҮгҖӮжҹҗ银иЎҢе®ўжҲ·еңЁAIStationжҷәиғҪе®№й”ҷзҡ„жңәеҲ¶дҝқйҡңдёӢпјҢеңЁжһҒе…¶дёҘиӢӣзҡ„дёҡеҠЎжҠ•дә§жөӢиҜ•дёӯиғҪеӨҹе®һзҺ°еҝ«йҖҹж•…йҡңжҺ’жҹҘе’ҢжҒўеӨҚпјҢеӨ§е№…йҷҚдҪҺдёҡеҠЎжҠ•дә§дёҠзәҝж—¶й—ҙгҖӮ
AIStationеҠ©еҠӣиЎҢдёҡжҸҗеҚҮеӨ§жЁЎеһӢејҖеҸ‘ж•ҲзҺҮ
AIStationе№іеҸ°еңЁAIејҖеҸ‘гҖҒеә”з”ЁйғЁзҪІе’ҢеӨ§жЁЎеһӢе·ҘзЁӢе®һи·өдёҠз§ҜзҙҜдәҶе®қиҙөзҡ„з»ҸйӘҢе’ҢжҠҖжңҜпјҢеё®еҠ©иҜёеӨҡиЎҢдёҡе®ўжҲ·еңЁиө„жәҗгҖҒејҖеҸ‘гҖҒйғЁзҪІеұӮйқўе®һзҺ°йҷҚжң¬еўһж•ҲгҖӮеңЁеһӮзӣҙиЎҢдёҡйўҶеҹҹпјҢAIStationе№іеҸ°её®еҠ©еӨҙйғЁйҮ‘иһҚе®ўжҲ·гҖҒз”ҹзү©еҲ¶иҚҜжңҚеҠЎе…¬еҸёеҝ«йҖҹеҲ©з”ЁеҜҶйӣҶж•°жҚ®и®ӯз»ғгҖҒйӘҢиҜҒеӨ§жЁЎеһӢпјҢеӨ§еӨ§йҷҚдҪҺеӨ§жЁЎеһӢдёҡеҠЎжҲҗжң¬гҖӮжҹҗеӨ§еһӢе•Ҷдёҡ银иЎҢеҹәдәҺAIStationжү“йҖ зҡ„并иЎҢиҝҗз®—йӣҶзҫӨпјҢеҮӯеҖҹйўҶе…Ҳзҡ„еӨ§и§„жЁЎеҲҶеёғејҸи®ӯз»ғж”Ҝж’‘иғҪеҠӣпјҢиҚЈиҺ·2022 IDCвҖңжңӘжқҘж•°еӯ—еҹәзЎҖжһ¶жһ„йўҶеҶӣиҖ…вҖқеҘ–йЎ№гҖӮ
жөӘжҪ®дҝЎжҒҜAIStationеңЁеӨ§жЁЎеһӢж–№йқўе·Із»ҸеҸ–еҫ—дәҶиҜёеӨҡдёҡз•ҢйўҶе…Ҳзҡ„з»ҸйӘҢе’Ңз§ҜзҙҜпјҢе®һзҺ°дәҶз«ҜеҲ°з«Ҝзҡ„дјҳеҢ–пјҢжҳҜжӣҙйҖӮеҗҲеӨ§жЁЎеһӢж—¶д»Јзҡ„дәәе·ҘжҷәиғҪе№іеҸ°гҖӮжңӘжқҘAIStationе°ҶдёҺжөӘжҪ®дҝЎжҒҜOGAIиҪҜ件ж ҲдёҖеҗҢиҝӣеҢ–пјҢиҝӣдёҖжӯҘйҖҡиҝҮдҪҺд»Јз ҒгҖҒж ҮеҮҶеҢ–зҡ„еӨ§жЁЎеһӢејҖеҸ‘жөҒзЁӢпјҢд»ҘеҸҠдҪҺжҲҗжң¬е’Ңй«ҳж•Ҳзҡ„жҺЁзҗҶжңҚеҠЎйғЁзҪІпјҢеё®еҠ©е®ўжҲ·еҝ«йҖҹе®һзҺ°еӨ§жЁЎеһӢејҖеҸ‘е’ҢиҗҪең°пјҢжҠўеҚ е…ҲжңәгҖӮ
жөӘжҪ®дҝЎжҒҜеҲҶеёғејҸеӯҳеӮЁAS13000-HпјҢжөӘжҪ®дҝЎжҒҜAS13000-MеӯҳеӮЁе№іеҸ°пјҢжөӘжҪ®дҝЎжҒҜеӯҳеӮЁSSD NS6610G1
жҷәз®—OS NF5468 NF8260G7
жҲҗйғҪ科жұҮ科жҠҖжңүйҷҗе…¬еҸё
ең°еқҖпјҡжҲҗйғҪеёӮдәәж°‘еҚ—и·Ҝеӣӣж®ө1еҸ·ж—¶д»Јж•°з ҒеӨ§еҺҰ18FA5
з”өиҜқпјҡ400-028-1235
жүӢжңәпјҡ180 8195 0517 пјҲеҫ®дҝЎеҗҢеҸ·пјү

